This Virtual Lab demonstrates the process of extracting text from two images using Optical Character Recognition (OCR) technique and comparing their content using Natural Language Processing (NLP) techniques to enable machines to approximate human-like understanding of textual similarity.
Aim
Theory & Applications
Text recognition from an image requires integration of Optical Character Recognition (OCR) and Natural Language Processing (NLP) techniques to compute the textual similarity between two images. The process involves extracting text from the image, pre-processing the text, converting it into a weighted vector representation using a commonly used method TF-IDF (Term Frequency-Inverse Document Frequency), and finally measuring their similarity using metric Cosine Similarity.
- Optical Character Recognition (OCR)
- Definition: OCR is a computer vision technique used to identify and extract alphanumeric text from images using pattern recognition, convolutional models, or deep learning techniques.
- Functionality: It converts pixel-level image data into text by recognizing character shapes and structures.
- Tool Used: OCR.space API is used to perform high-accuracy text extraction including support for the handwritten content, and returns extracted text in a JSON format. While open-source libraries like Tesseract and EasyOCR can also be used for this task, they are primarily optimized for printed or clearly structured text and often underperform on real-world handwritten images. OCR.space API gives better results due to its training on diverse datasets.
- Natural Language Processing (NLP)
- Definition: NLP refers to the set of algorithms and processes that allow machines to understand, interpret, and manipulate human language.
- Library Used: nltk (Natural Language Toolkit)
- Text Pre-processing: A crucial stage that prepares raw text for similarity analysis.
It includes:
- Lowercasing: Converts all characters to lowercase to standardize the text.
- Handling Punctuation & Special Characters: Stripped to avoid irrelevant variation between texts.
- Tokenization: The process of breaking text into smaller units called tokens (typically words). For example, "Text similarity project" → ["text", "similarity", "project"]
- Stopword Removal: Removes common words (like “is”, “the”, “of”) that carry little semantic weight and don't contribute significantly to similarity measures.
- Lemmatization: Reduces each word to its base or dictionary form, which ensures that related terms (e.g., "jumps", "jumping", "jumped") are treated as the same core concept. This improves semantic matching
- TF-IDF (Term Frequency – Inverse Document Frequency)
- Purpose: Measures a term's importance by giving more weight to rare words and less weight to common words that appear across all documents.
- Library Used: sklearn (scikit-learn)
- Term Frequency (TF): Measures how frequently a term t appears in a text:
TF(t) = (Number of times term t appears in a text) / (Total terms in text) - Inverse Document Frequency (IDF): Reduces the weight of common terms by using the below formula:
IDF(t) = log(Number of texts / Number of texts with term t) - TF-IDF Score:
TF-IDF(t) = TF(t) × IDF(t) - This representation allows modelling of text as vectors in a high-dimensional space where each dimension corresponds to a term’s weight.
- Cosine Similarity
- Definition: Cosine similarity is a metric used to measure how similar two vectors are, regardless of their magnitude.
- Library Used: sklearn (scikit-learn)
- Mathematical Formula:
Cosine Similarity = (A · B) / (||A|| × ||B||)
where A and B are the TF-IDF vectors of two texts. - Interpretation: The result ranges from 0% to 100%:
- 100% → identical direction → highly similar
- 0% → orthogonal → completely dissimilar
- Text-Based Image Comparison for Academic Integrity: Educational platforms can use this system to compare scanned handwritten or printed assignments to detect content overlap using cosine similarity on pre-processed TF-IDF vectors — useful for plagiarism detection where traditional text matching tools fail.
- Duplicate Document Detection in Digital Archives: In large archives of scanned documents (legal files, forms, contracts), this technique can identify duplicate or near-duplicate text content across differently formatted or handwritten copies by comparing their TF-IDF representations.
- Automated Metadata Tagging for Scanned Content: When indexing a large number of scanned pages, NLP can be used to extract and summarize dominant terms using TF-IDF weights. These terms can be used to automatically generate tags or categories.
- Evidence Matching in Digital Forensics: Investigators can analyze and compare handwritten notes or printed letters using OCR and cosine similarity to find textual overlaps, especially when content is disguised or reformatted.
- Document Clustering and Organization: By generating TF-IDF vectors from scanned images, documents can be grouped into clusters (e.g., job applications, receipts letters) for tagging them based on textual similarity without manual sorting, which is useful in information retrieval systems and customer segmentation.
Procedure
- Upload Input Images
- Select two image files that contain textual content (e.g., typed documents, printed forms, or handwritten notes).
- The interface provides two separate upload fields for Image 1 and Image 2.
- Perform OCR on Uploaded Images
- Click the "Extract Text" button.
- Each image is sent to the OCR.space API.
- The API returns the extracted text for both images separately.
- The extracted text is displayed on the screen for verification.
- Pre-process the Extracted Text
- Click the "Pre-process Text" button.
- The following pre-processing steps are applied to each extracted text:
- Lowercasing
- Removing punctuation and special characters
- Tokenization (splitting text into words)
- Stopword removal (removing common words like "the", "and", "is")
- Lemmatization (reducing each word to its base or dictionary form, e.g., "running" → "run")
- The cleaned and tokenized text is then shown on the interface.
- Vectorize the Text using TF-IDF
- The pre-processed texts from both images are converted into TF-IDF vectors referred as A and B respectively.
- Each term is assigned a numerical weight based on its importance in the document and rarity across documents.
- Calculate Cosine Similarity
- Click the "Calculate Similarity" button.
- Cosine Similarity is calculated using the TF-IDF vectors:
Cosine Similarity = (A · B) / (||A|| × ||B||)Where:
-
A and B are d-dimensional vectors represented as
A = (A1, A2, ..., Ad)andB = (B1, B2, ..., Bd). -
A · B is the dot product, calculated as:
A1 × B1 + A2 × B2 + ... + Ad × Bd -
||A|| is the magnitude of vector A, computed as:
√(A12 + A22 + ... + Ad2) - ||B|| is the magnitude of vector B, computed similarly.
-
A and B are d-dimensional vectors represented as
- A similarity score between 0 and 1 is then computed and displayed, indicating how similar the two texts are based on their content.
- Interpret the Result
- The cosine similarity score ranges from 0 to 1, which is equivalent to a similarity percentage ranging from 0% to 100%
- 100% → Vectors point in identical directions → Highly similar texts (not necessarily identical wording)
- 0% → Vectors are orthogonal → Completely dissimilar texts
Code
Example program
from flask import Flask, request, jsonify, render_template
from flask_cors import CORS
import requests
import os
import re
import nltk
import string
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from dotenv import load_dotenv
load_dotenv()
OCR_API_KEY = os.getenv("OCR_API_KEY")
app = Flask(__name__)
CORS(app)
UPLOAD_FOLDER = 'uploads'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
if not os.path.exists(UPLOAD_FOLDER):
os.makedirs(UPLOAD_FOLDER)
# Function to call the OCR.space API
def ocr_space_file(filename):
payload = {
'isOverlayRequired': False,
'apikey': OCR_API_KEY,
'language': 'eng',
'OCREngine': 2
}
with open(filename, 'rb') as f:
response = requests.post('https://api.ocr.space/parse/image',
files={filename: f},
data=payload)
return response.json()
@app.route('/')
def index():
return render_template('index.html')
# Download NLTK resources
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')
stopwords_english = set(stopwords.words('english'))
additional_punctuation = set(string.punctuation)
lemmatizer = WordNetLemmatizer()
# Clean unwanted characters from the OCR extracted text
def clean_extracted_text(text):
cleaned_text = re.sub(r'[→V]', '', text)
return cleaned_text.strip()
# Pre-process text: lowercase, remove stopwords & punctuation, lemmatize
def preprocess_text(text):
text = text.lower()
text = clean_extracted_text(text)
tokens = word_tokenize(text)
processed_tokens = [
lemmatizer.lemmatize(token)
for token in tokens
if token not in stopwords_english and token not in additional_punctuation
]
# Join tokens back into a string
processed_text = " ".join(processed_tokens)
return processed_text
# Compare two texts using TF-IDF and cosine similarity
def compare_tfidf_cosine(text1, text2):
# Preprocess the texts
processed_text1 = preprocess_text(text1)
processed_text2 = preprocess_text(text2)
print(processed_text1, "\n")
print(processed_text2, "\n")
# Vectorize texts with TF-IDF
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([processed_text1, processed_text2])
# Compute cosine similarity (returns a 2x2 matrix)
cosine_sim_matrix = cosine_similarity(tfidf_matrix)
print(cosine_sim_matrix, "\n")
similarity = cosine_sim_matrix[0][1] * 100 # convert to percentage
print("Similarity : ", similarity)
return round(similarity, 2)
@app.route("/api/upload/", methods=["POST"])
def upload_files():
if "image1" not in request.files or "image2" not in request.files:
return jsonify({"error": "Both images are required"}), 400
image1 = request.files["image1"]
image2 = request.files["image2"]
image1_path = os.path.join(app.config['UPLOAD_FOLDER'], "image1.png")
image2_path = os.path.join(app.config['UPLOAD_FOLDER'], "image2.png")
image1.save(image1_path)
image2.save(image2_path)
result1 = ocr_space_file(image1_path)
result2 = ocr_space_file(image2_path)
print("OCR Result 1:", result1)
print("OCR Result 2:", result2)
text1 = result1.get("ParsedResults", [{}])[0].get("ParsedText", "")
text2 = result2.get("ParsedResults", [{}])[0].get("ParsedText", "")
if not text1 or not text2:
return jsonify({"error": "Failed to extract text from images"}), 500
similarity_score = compare_tfidf_cosine(text1, text2)
print("Similarity Score :", similarity_score)
return jsonify({"similarity_score": similarity_score})
if __name__ == "__main__":
app.run(debug=True)
Practice
Example 1 and Example 2 illustrate the complete workflow using two sample images. No user input is required.
In Try Yourself users are required to upload two custom images. The OCR and textual similarity analysis are then performed on the uploaded content.
In Try Yourself users are required to upload two custom images. The OCR and textual similarity analysis are then performed on the uploaded content.
This example demonstrates the full pipeline of the experiment using two sample images. Each stage illustrates how the content is transformed from raw image data to a final similarity score.
Now consider the following two images are uploaded by the user:
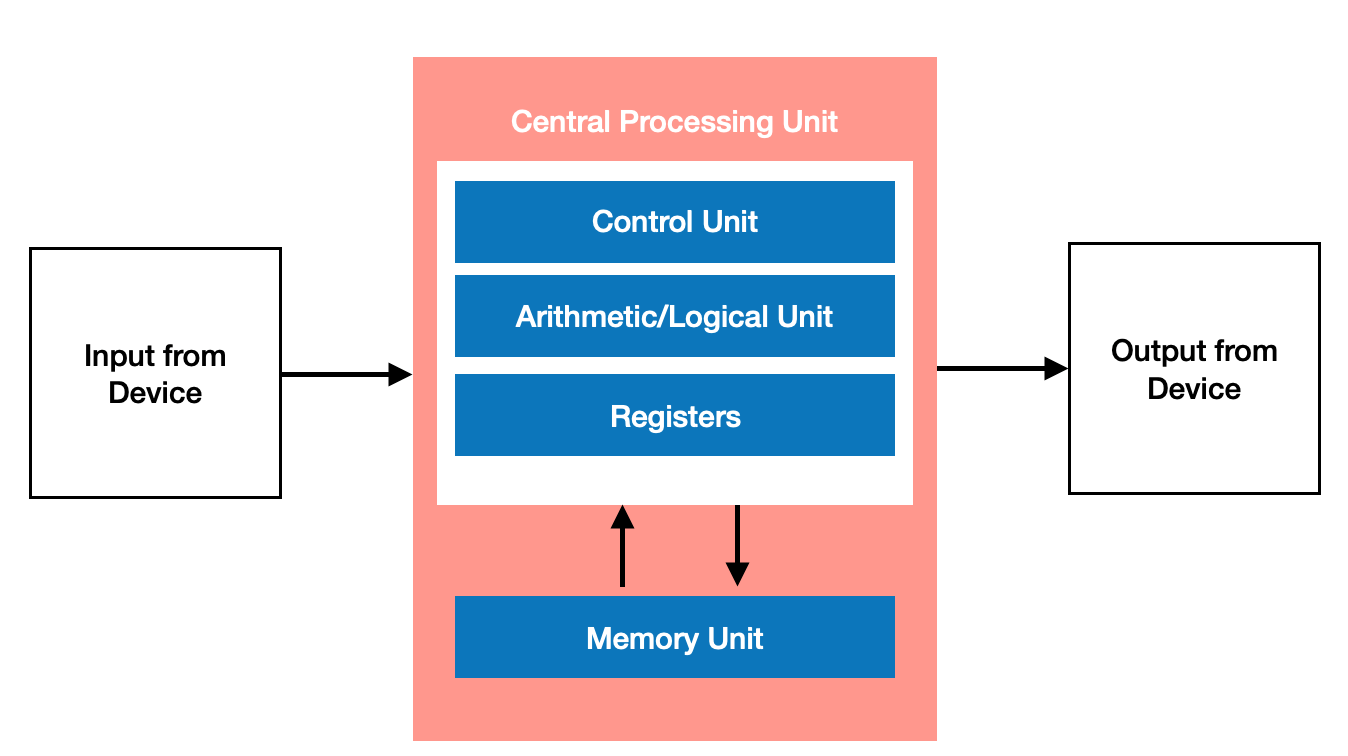

After clicking the “Extract Text” button, each image is sent to the OCR.space API. The API processes the image and returns the detected text.
Text Extracted
Image 1: Input from\nDevice\nCentral Processing Unit\nControl Unit\nArithmetic/Logical Unit\nRegisters\nMemory Unit\nOutput from\nDevice
Image 2:Input Unit\nCPU\nControl Unit\nArithmetic\n& Logic Unit\nMemory Unit\nOutput Unit
Note: The "\n" symbols in the extracted text represent line breaks, indicating where a new line begins in the original image content.
Before comparing the extracted texts, pre-processing is essential to clean and standardize the content. This step ensures that insignificant variations (like punctuation or casing) do not affect the similarity result.
After Lowercasing
Image 1: input from\ndevice\ncentral processing unit\ncontrol unit\narithmetic/logical unit\nregisters\nmemory unit\noutput from\ndevice
Image 2: input unit\ncpu\ncontrol unit\narithmetic\n& logic unit\nmemory unit\noutput unit
After Punctuation Removal
Image 1: input from\ndevice\ncentral processing unit\ncontrol unit\narithmetic logical unit\nregisters\nmemory unit\noutput from\ndevice
Image 2: input unit\ncpu\ncontrol unit\narithmetic\nlogic unit\nmemory unit\noutput unit
After Tokenization
Image 1: ['input', 'from', 'device', 'central', 'processing', 'unit', 'control', 'unit', 'arithmetic', 'logical', 'unit', 'registers', 'memory', 'unit', 'output', 'from', 'device']
Image 2: ['input', 'unit', 'cpu', 'control', 'unit', 'arithmetic', 'logic', 'unit', 'memory', 'unit', 'output', 'unit']
After Stopword Removal
Image 1: input device central processing unit control unit arithmetic logical unit registers memory unit output device
Image 2: input unit cpu control unit arithmetic logic unit memory unit output unit
After Lemmatization
Image 1: input device central process unit control unit arithmetic logical unit register memory unit output device
Image 2: input unit cpu control unit arithmetic logic unit memory unit output unit
The cleaned tokens obtained after all pre-processing steps are now transformed into numerical vectors using TF-IDF (Term Frequency – Inverse Document Frequency). TF-IDF helps in assigning weights to words based on their importance — terms that are frequent in a document but rare across other documents are given more significance.
TF-IDF Score Formula (simplified):
TF-IDF(t, d) = TF(t, d) × IDF(t)
Where:
– TF(t, d): Term Frequency – how many times term t appears in document d
– IDF(t): Inverse Document Frequency = log[(N + 1) / (DF + 1)] + 1
Note: You may notice a slight change in the formula of IDF compared to the traditional form.
This version — log((N + 1) / (DF + 1)) + 1 — is commonly used in implementations like TfidfVectorizer from sklearn library to prevent division-by-zero and stabilize the values when working with small datasets. Adding 1 to both numerator and denominator is known as smoothing, and it helps ensure more balanced weight distribution across rare and common terms.
The following matrix shows the TF-IDF weights assigned to each term in Image 1 and Image 2 after vectorization:

After converting the pre-processed text from both images into TF-IDF vectors, we compute the cosine similarity between them. Using Cosine Similarity Formula:
cos(θ) = (A · B) / (||A|| × ||B||)
The result is presented in the form of a similarity matrix, where each element (i, j) represents the similarity between Document i and Document j. The matrix shown below is the actual cosine similarity matrix obtained in this case.
Cosine Similarity Matrix:
[[1.0 0.7073] [0.7073 1.0]]
The value 0.7073 indicates the similarity score between the two uploaded images.
Similarity Score: 70.73%
This example demonstrates the full pipeline of the experiment using two sample images. Each stage illustrates how the content is transformed from raw image data to a final similarity score.
Now consider the following two images are uploaded by the user:
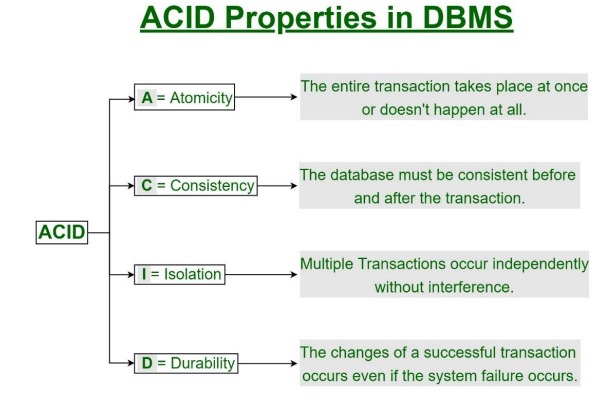

After clicking the “Extract Text” button, each image is sent to the OCR.space API. The API processes the image and returns the detected text.
Text Extracted
Image 1: ACID\nACID Properties in DBMS\n• A = Atomicity'\n* The entire transaction takes place at once\nor doesn't happen at all.\n* C = Consistency\n, The database must be consistent before\nand after the transaction.\n• = Isolation\n→ Multiple Transactions occur independently\nwithout interference.\n> D = Durability -\n→ The changes of a successful transaction\noccurs even if the system failure occurs.
Image 2:A transaction is a set of database\noperations done\nas one unit\nIt follows ACID Property.\nAtomicity, Consistency\nIsolation, Durability
Note: The "\n" symbols in the extracted text represent line breaks, indicating where a new line begins in the original image content.
Before comparing the extracted texts, pre-processing is essential to clean and standardize the content. This step ensures that insignificant variations (like punctuation or casing) do not affect the similarity result.
After Lowercasing
Image 1: acid\nacid properties in dbms\n• a = atomicity'\n* the entire transaction takes place at once\nor doesn't happen at all.\n* c = consistency\n, the database must be consistent before\nand after the transaction.\n• = isolation\n→ multiple transactions occur independently\nwithout interference.\n> d = durability -\n→ the changes of a successful transaction\noccurs even if the system failure occurs.
Image 2: a transaction is a set of database\noperations done\nas one unit\nit follows acid property.\natomicity, consistency\nisolation, durability
After Punctuation Removal
Image 1: acid\nacid properties in dbms\n a atomicity\n the entire transaction takes place at once\nor doesnt happen at all\n c consistency\n the database must be consistent before\nand after the transaction\n isolation\n multiple transactions occur independently\nwithout interference\n d durability \n the changes of a successful transaction\noccurs even if the system failure occurs
Image 2: a transaction is a set of database\noperations done\nas one unit\nit follows acid property \natomicity consistency\nisolation durability
After Tokenization
Image 1: ['acid', 'acid', 'properties', 'in', 'dbms', 'a', 'atomicity', 'the', 'entire', 'transaction', 'takes', 'place', 'at', 'once', 'or', 'doesnt', 'happen', 'at', 'all', 'c', 'consistency', 'the', 'database', 'must', 'be', 'consistent', 'before', 'and', 'after', 'the', 'transaction', 'isolation', 'multiple', 'transactions', 'occur', 'independently', 'without', 'interference', 'd', 'durability', 'the', 'changes', 'of', 'a', 'successful', 'transaction', 'occurs', 'even', 'if', 'the', 'system', 'failure', 'occurs']
Image 2: ['a', 'transaction', 'is', 'a', 'set', 'of', 'database', 'operations', 'done', 'as', 'one', 'unit', 'it', 'follows', 'acid', 'property', 'atomicity', 'consistency', 'isolation', 'durability']
After Stopword Removal
Image 1: acid acid properties dbms atomicity entire transaction takes place doesnt happen c consistency database must consistent transaction isolation multiple transactions occur independently without interference durability changes successful transaction occurs even system failure occurs
Image 2: transaction set database operations done one unit follows acid property atomicity consistency isolation durability
After Lemmatization
Image 1: acid acid property dbms atomicity entire transaction take place doesnt happen c consistency database must consistent transaction isolation multiple transaction occur independently without interference durability change successful transaction occurs even system failure occurs
Image 2: transaction set database operation done one unit follows acid property atomicity consistency isolation durability
The cleaned tokens obtained after all pre-processing steps are now transformed into numerical vectors using TF-IDF (Term Frequency – Inverse Document Frequency). TF-IDF helps in assigning weights to words based on their importance — terms that are frequent in a document but rare across other documents are given more significance.
TF-IDF Score Formula (simplified):
TF-IDF(t, d) = TF(t, d) × IDF(t)
Where:
– TF(t, d): Term Frequency – how many times term t appears in document d
– IDF(t): Inverse Document Frequency = log[(N + 1) / (DF + 1)] + 1
Note: You may notice a slight change in the formula of IDF compared to the traditional form.
This version — log((N + 1) / (DF + 1)) + 1 — is commonly used in implementations like TfidfVectorizer from sklearn library to prevent division-by-zero and stabilize the values when working with small datasets. Adding 1 to both numerator and denominator is known as smoothing, and it helps ensure more balanced weight distribution across rare and common terms.
The following matrix shows the TF-IDF weights assigned to each term in Image 1 and Image 2 after vectorization:

After converting the pre-processed text from both images into TF-IDF vectors, we compute the cosine similarity between them. Using Cosine Similarity Formula:
cos(θ) = (A · B) / (||A|| × ||B||)
The result is presented in the form of a similarity matrix, where each element (i, j) represents the similarity between Document i and Document j. The matrix shown below is the actual cosine similarity matrix obtained in this case.
Cosine Similarity Matrix:
[[1.0000 0.2913] [0.2913 1.0000]]
The value 0.2872 indicates the similarity score between the two uploaded images.
Similarity Score: 28.72%
Upload Image 1
Upload Image 2
Extracted Text 1
Extracted Text 2
Pre-processed Text 1
Pre-processed Text 2
Similarity: Not Calculated
Result
Text extracted from two images and subsequently pre-processed are compared to get a similarity score using cosine similarity metric. The resultant score offers a quantitative measure of closeness of the selected images in terms of written textual details.
Interpretation of the result:
- Score close to 100%: The texts in both images are nearly or completely identical.
- Score close to 0%: The texts are entirely different with no significant overlap.
- Intermediate score: The texts have partial similarity — they may share some common phrases or keywords but differ in structure or content.
This result helps users understand the degree of similarity between scanned documents, handwritten notes, or printed forms. It highlights the impact of pre-processing (like stopword removal and tokenization) and shows how semantic closeness can be identified even when wording slightly varies.
Example:
- Image 1 text: "Machine learning is transforming modern industries."
- Image 2 text: "Modern industries are being changed by machine learning."
- Similarity Score: 82%
Although these two sentences are written differently, their underlying meaning (core idea) is the same — that is, they are synonymous sentences. Such semantic textual similarity is captured using natural language processing techniques.
Quiz
Select the most appropriate choice
References
- 1. OCR.space. (n.d.). Get Your Free OCR API Key. Retrieved June 30, 2025, from https://ocr.space/ocrapi
- 2. Bird, S., Klein, E., & Loper, E. (Aug 19, 2024). NLTK: Natural Language Toolkit. Retrieved June 30, 2025, from https://www.nltk.org/
- 3. Scikit-learn Developers. (n.d.). TfidfVectorizer - scikit-learn 1.7.0 Documentation. Retrieved June 30, 2025, from https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
- 4. Scikit-learn Developers. (n.d.). cosine_similarity - scikit-learn 1.7.0 Documentation. Retrieved June 30, 2025, from https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise.cosine_similarity.html
Team & Tools
Students
- Kriti Misra, 2nd year, BSc (Hons) Computer Science (2024-25)
- Himanshu Yadav, 2nd year, BSc (Hons) Computer Science (2024-25)
Mentors
- Prof. Sharanjit Kaur, Department of Computer Science
- Ms. Priyanka Sharma, Department of Computer Science
- Ms. Nishu Singh, Department of Computer Science
Tools Used
- 1. OCR.space API - for text extraction
- 2. NLTK (Natural Language Toolkit), v3.9.1 - for text pre-processing
- 3. scikit-learn, v1.7.0 - for calculating similarity
- 4. Vanilla HTML, CSS, JS - for creating the web page
- 5. Flask, v3.1.1 - for backend